The challenge
Every sentiment and intent model we trained started the same way: engineers hand-classifying thousands of consumer messages in a spreadsheet. It was slow and exhausting, and after enough hours of it, people started making mistakes they wouldn't have made fresh — misclicks, inconsistent calls, the kind of noise that shows up in a model's accuracy months later.
“After annotating for a while... I get tired and I end up misclicking a lot.”
— Data Annotation Specialist
Process
Interviews with the people doing the labeling, plus a look at how Prodigy and Label Studio handled the same problem, pointed to three rules: keyboard-first so hands never leave the row, a visual hierarchy calm enough to survive hour four of a shift, and confirmation steps that catch a bad click before it becomes bad training data.
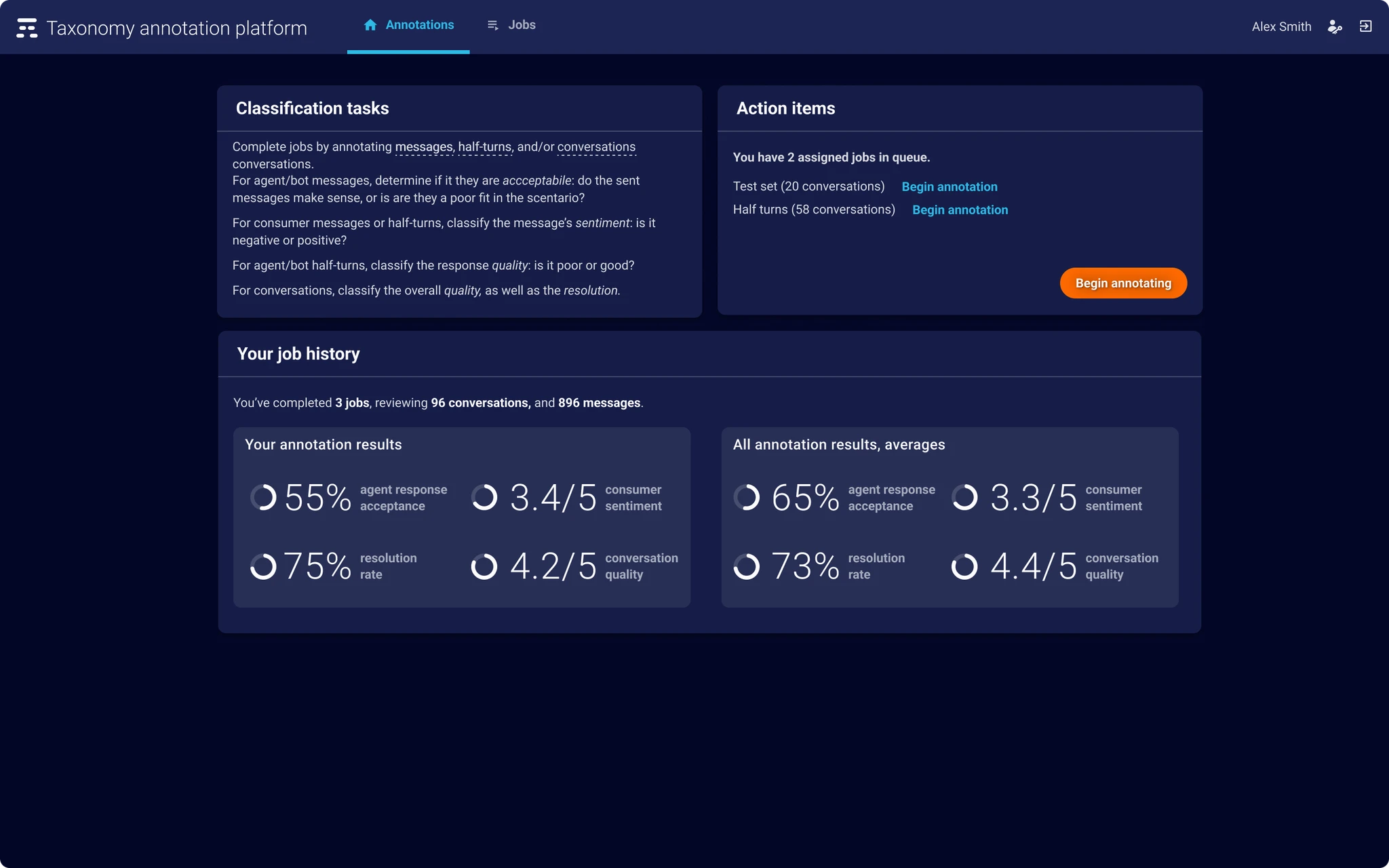
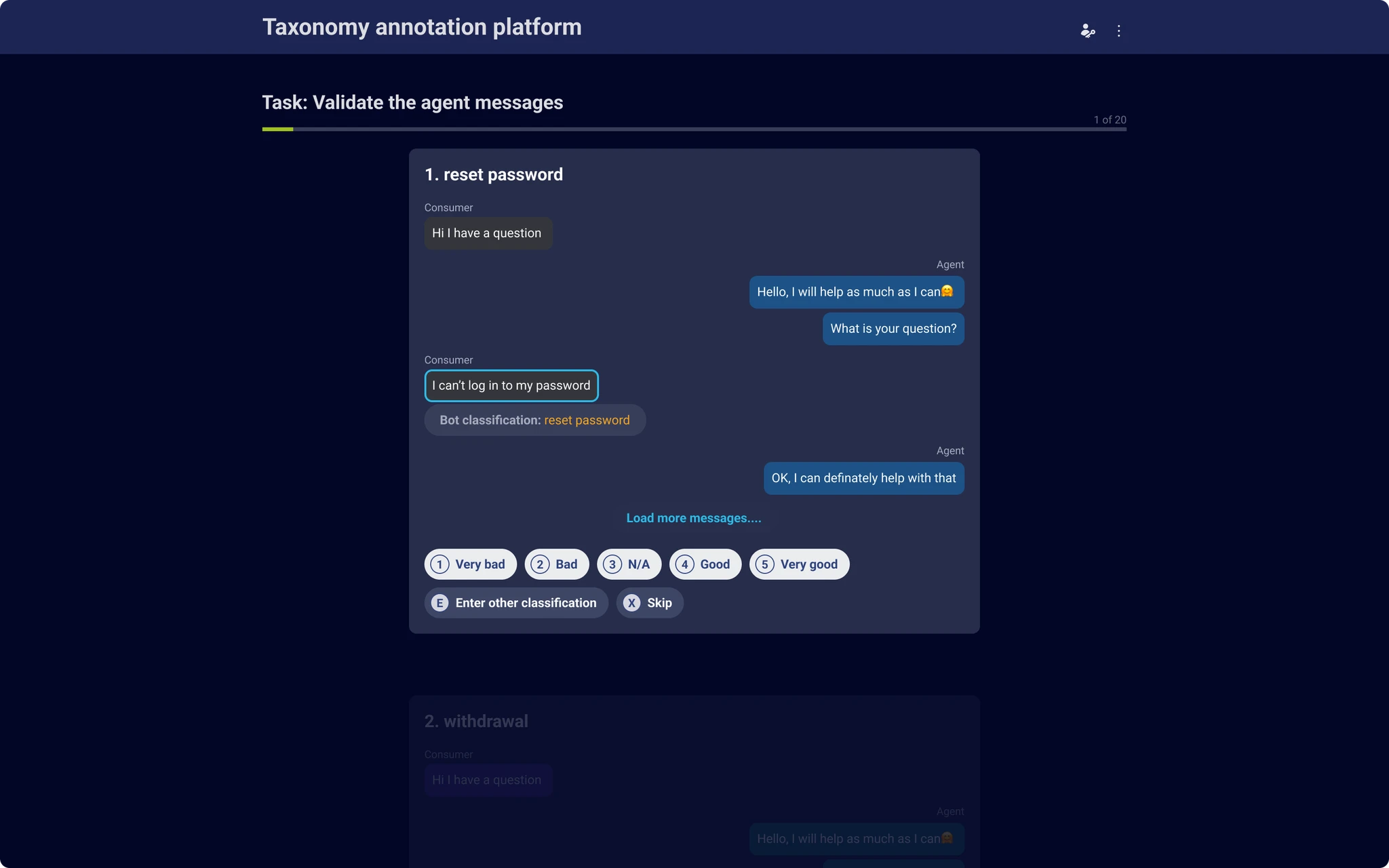
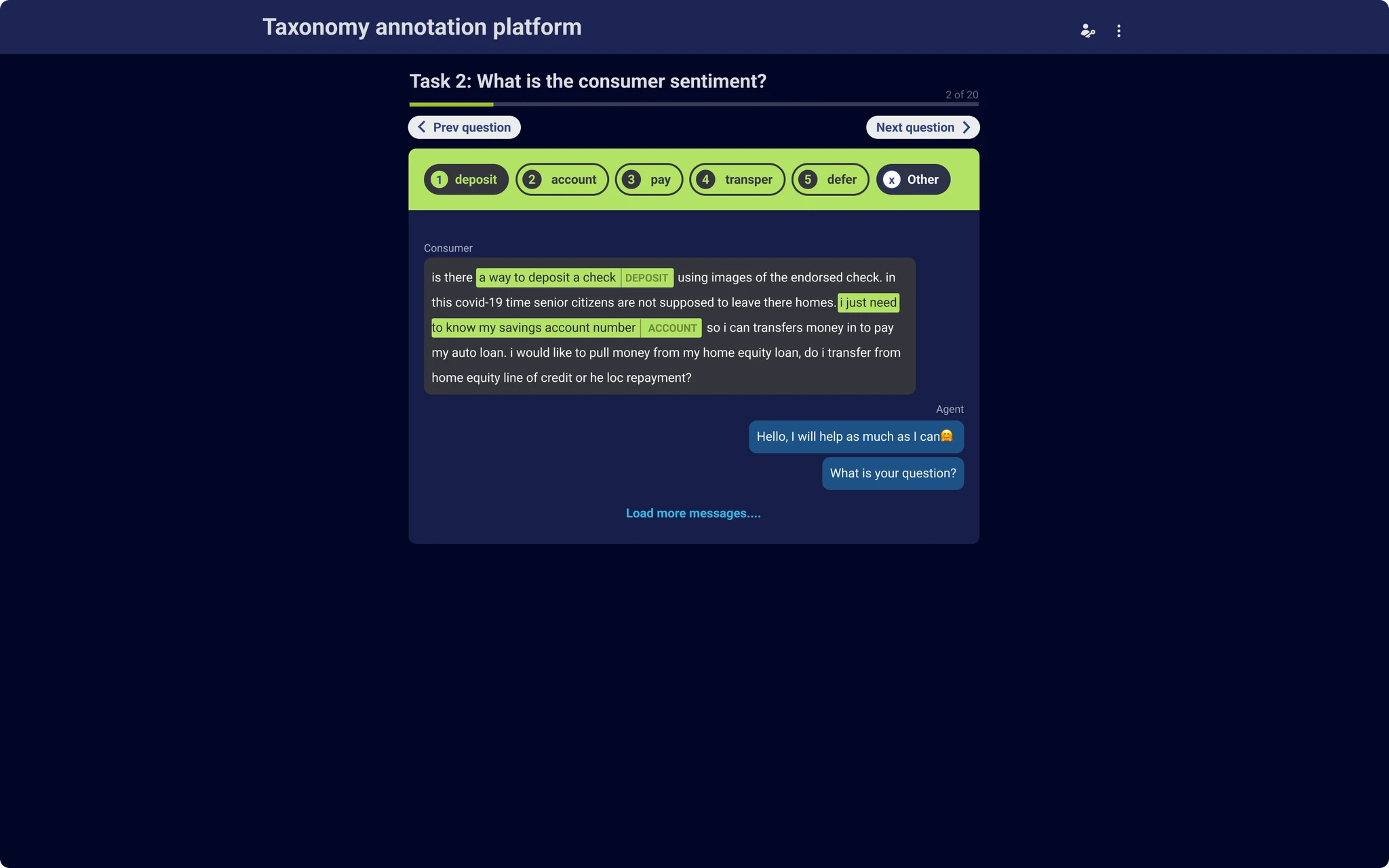
Results
- 86% faster than spreadsheets
- 15% fewer annotation errors
- Full team adoption within a week
- Model training cycles: quarterly → monthly
“This is much better to use than working with spreadsheets. Reading the text is much easier, I make fewer mistakes, and I'm much faster at annotation.”
— Lar, Insights Manager
Reflections
Efficiency beat feature count. Keyboard shortcuts and fewer ways to make a mistake solved the actual problem without anything that would slow adoption down.
Inter-annotator agreement — how often two people tag the same message the same way — should have been a day-one metric, not something bolted on after launch.